|
Код |
Наименование КБК |
|---|---|
|
Страховые взносы на ОМС работающего населения |
|
|
182 1 02 02101 08 1013 160 |
Страховые взносы на обязательное медицинское страхование работающего населения, зачисляемые в бюджет Федерального фонда обязательного медицинского страхования (страховые взносы на обязательное медицинское страхование работающего населения за расчетные периоды, начиная с 1 января 2017 года) |
|
182 1 02 02101 08 2013 160 |
Страховые взносы на обязательное медицинское страхование работающего населения, зачисляемые в бюджет Федерального фонда обязательного медицинского страхования (пени по страховым взносам на обязательное медицинское страхование работающего населения за расчетные периоды, |
|
182 1 02 02101 08 3013 160 |
Страховые взносы на обязательное медицинское страхование работающего населения, зачисляемые в бюджет Федерального фонда обязательного медицинского страхования (суммы денежных взысканий (штрафов) по страховым взносам на обязательное медицинское страхование работающего населения за расчетные периоды, начиная с 1 января 2017 года) |
|
182 1 02 02101 08 1011 160 |
Страховые взносы на обязательное медицинское страхование работающего населения, зачисляемые в бюджет Федерального фонда обязательного медицинского страхования (страховые взносы на обязательное медицинское страхование работающего населения за расчетные периоды, истекшие до 1 января 2017 года) |
|
182 1 02 02101 08 2011 160 |
Страховые взносы на обязательное медицинское страхование работающего населения, зачисляемые в бюджет Федерального фонда обязательного медицинского страхования (пени по страховым взносам на обязательное медицинское страхование работающего населения за расчетные периоды, истекшие до 1 января 2017 года) |
|
182 1 02 02101 08 3011 160 |
Страховые взносы на обязательное медицинское страхование работающего населения, зачисляемые в бюджет Федерального фонда обязательного медицинского страхования (суммы денежных взысканий (штрафов) по страховым взносам на обязательное медицинское страхование работающего населения за расчетные периоды, истекшие до 1 января 2017 года) |
|
182 1 02 02103 08 1013 160 |
Страховые взносы на обязательное медицинское страхование работающего населения в фиксированном размере, зачисляемые в бюджет Федерального фонда обязательного медицинского страхования (страховые взносы на обязательное медицинское страхование работающего населения за расчетные периоды, |
|
182 1 02 02103 08 1011 160 |
Страховые взносы на обязательное медицинское страхование работающего населения в фиксированном размере, зачисляемые в бюджет Федерального фонда обязательного медицинского страхования (страховые взносы на обязательное медицинское страхование работающего населения за расчетные периоды, истекшие до 1 января 2017 года) |
|
182 1 02 02103 08 2013 160 |
Страховые взносы на обязательное медицинское страхование работающего населения в фиксированном размере, зачисляемые в бюджет Федерального фонда обязательного медицинского страхования (пени по страховым взносам на обязательное медицинское страхование работающего населения за расчетные периоды, начиная с 1 января 2017 года) |
|
182 1 02 02103 08 2011 160 |
Страховые взносы на обязательное медицинское страхование работающего населения в фиксированном размере, зачисляемые в бюджет Федерального фонда обязательного медицинского страхования (пени по страховым взносам на обязательное медицинское страхование работающего населения за расчетные периоды, истекшие до 1 января 2017 года) |
|
182 1 02 02103 08 3013 160 |
Страховые взносы на обязательное медицинское страхование работающего населения в фиксированном размере, зачисляемые в бюджет Федерального фонда обязательного медицинского страхования (суммы денежных взысканий (штрафов) по страховым взносам на обязательное медицинское страхование работающего населения за расчетные периоды, |
|
182 1 02 02103 08 3011 160 |
Страховые взносы на обязательное медицинское страхование работающего населения в фиксированном размере, зачисляемые в бюджет Федерального фонда обязательного медицинского страхования (суммы денежных взысканий (штрафов) по страховым взносам на обязательное медицинское страхование работающего населения за расчетные периоды, истекшие до 1 января 2017 года) |
КБК 2020 и 2021 — коды бюджетной классификации КБК на 2020 и 2021 год в России
КБК — эта аббревиатура знакома каждому бухгалтеру, а также абсолютно всем операционистам банков и работникам бюджетных учреждений.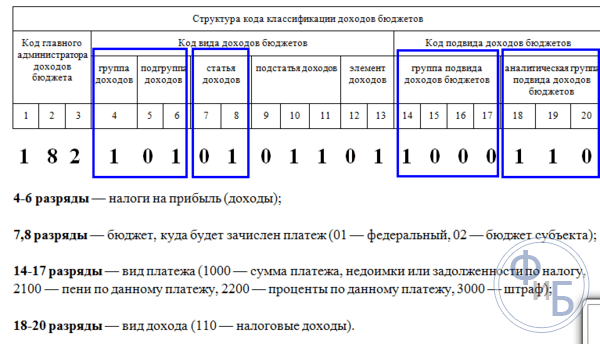
Коды бюджетной классификации — так расшифровываем мы эту аббревиатуру. Наличием этого понятия мы обязаны одному из основополагающих документов российского права — Бюджетному кодексу. Согласно этому документу, КБК определяется как группировка расходов, доходов и источников формирования государственного бюджета.
Как это объяснить проще и зачем на практике эти КБК нужны финансистам?
Сугубо практическое применение для преимущественного большинства обычных бухгалтеров таково: в любом платежном поручении на перечисление налогов, сборов, взносов, штрафов (в общем, любых денег, которые мы отдаем бюджету) обязан быть указан правильный код бюджетной классификации. Это будет залогом того, что деньги уйду в правильном направлении, а компания не получит проблем или штрафных санкций.
Можно привести очень простое и приблизительное, но образное сравнение. КБК — это своеобразный аналог расчетного счета компании. Если мы оплачиваем услугу партнера, то в платежке нам нужно указать тот счет, на который мы переводим партнеру оговоренную плату.
Как выглядит код?
Во-первых, он длинный — в нем 20 цифр.
Во-вторых, он подобен конструктору, и эти 20 цифр разделены на 4 логически независимые части. Каждая из них несет специальную информацию, в которой мы сейчас и разберемся.
Первые три цифры — код госоргана.
Следующая одна цифра — код дохода (группа этого дохода).
Третьи две цифры — код налога или другого платежа.
Следующие 5 цифр обозначают статью и подстатью дохода.
Далее идут 2 цифры, по которым можно понять уровень бюджета (региональный, федеральный, или вообще бюджет одного из фондов — ПФР, ФСС и т. п.).
Далее стоят 4 ключевые цифры, которые определяют «причину» платежа. Здесь важно понимать, что причин таких может быть всего три — 1) уплата собственно налога (сбора, взноса), 2) уплата пени по нему, 3) уплата штрафа по нему.
Так, например, в КБК по налогу на прибыль будут стоять цифры: 1000 — при уплате самого налога, 3000 — при уплате штрафа, 2100 — таков кусочек КБК пени по налогу на прибыль.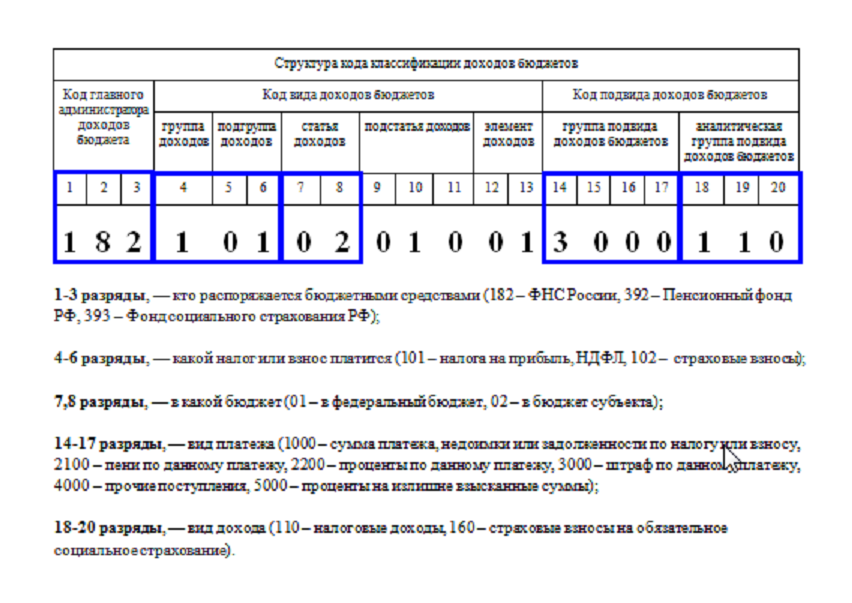
И, наконец, три последние цифры любого кода, — это классификатор вида доходов (налоговые, неналоговые, от собственности и т. д.).
Если рассмотреть в итоге один полный код на примере прибыль, то мы получим в 2020 году:
По уплате в федеральный бюджет:
КБК налога — 182 1 01 01011 01 1000 110
КБК пени по налогу на прибыль — 182 1 01 01011 01 2100 110
КБК штрафов — 182 1 01 01011 01 3000 110
И еще три кода будут соответствовать аналогичным платежам, но уже в бюджет региональный:
КБК налога — 182 1 01 01012 02 1000 110
КБК пени по налогу на прибыль — 182 1 01 01012 02 2100 110
КБК штрафов — 182 1 01 01012 02 3000 110
При сопоставлении этих цифр становится понятно, какая группа в коде за что отвечает. И сами коды уже не кажутся такими непонятными и пугающими.
Реквизиты ГБУЗ «Самарская областная клиническая психиатрическая больница»
Полное наименование: Государственное бюджетное учреждение здравоохранения «Самарская областная клиническая психиатрическая больница»
Краткое наименование: ГБУЗ «СОКПБ»
Свидетельство о внесении в Единый государственный реестр юридических лиц:
Серия 63 № 005068741 от 04. 12.1995г выдано ИФНС по Промышленному району г. Самары
12.1995г выдано ИФНС по Промышленному району г. Самары
ОГРН 1026301714735
ИНН 6319011294 КПП 631901001
КБК 00000000000000000130 мед.услуги, экспертиза
Банковские реквизиты:
МУФ СО (ГБУЗ «Самарская областная клиническая психиатрическая больница» л. сч 612010130)
Расчетный счет №40601810036013000002
Банк: Отделение Самара г. Самара
БИК 043601001
ФИО руководителя: главный врач Шейфер Михаил Соломонович на основании устава
Адрес, телефон: 443016 г. Самара ул. Нагорная, д.78
Тел.: (846) 207-40-30
Факс (846) 207-40-40
Коды статистики:
ГОСУДАРСТВЕННОЕ БЮДЖЕТНОЕ УЧРЕЖДЕНИЕ ЗДРАВООХРАНЕНИЯ «САМАРСКАЯ ОБЛАСТНАЯ КЛИНИЧЕСКАЯ ПСИХИАТРИЧЕСКАЯ БОЛЬНИЦА»
Свидетельство о государственной регистрации: № 1026301714735 от 14.12.2002
Общероссийский классификатор предприятий и организаций (ОКПО) — 01929330
Общероссийский классификатор объектов административно-территориального деления (ОКАТО) — 36401386000 (Промышленный)
Общероссийский классификатор территорий муниципальных образований (ОКТМО) — 36701335000 (Промышленный)
Общероссийский классификатор органов государственной власти и управления (ОКОГУ) — 2300229 (- здравоохранения)
Общероссийский классификатор форм собственности (ОКФС) — 13 (Собственность субъектов Российской Федерации)
Общероссийский классификатор организационно правовых форм (ОКОПФ) — 75203 (Государственные бюджетные учреждения субъектов Российской Федерации)
ОКВЭД — 86. 10
10Изменен Общероссийский классификатор территорий муниципальных образований
25.06.2020 10:09Информируем Вас об изменении Общероссийского классификатора территорий муниципальных образований (ОКТМО) для учета поступлений по штрафным санкциям (денежным взысканиям).
1. Банковские реквизиты для уплаты с 01.01.2020 года страхователями финансовых санкций, предусмотренных статьей 17 Федерального закона от 01.04.1996 № 27-ФЗ «Об индивидуальном (персонифицированном) учете в системе обязательного пенсионного страхования»
|
Наименование банковского реквизита |
Для страхователей, зарегистрированных в г. Москве |
Для страхователей, зарегистрированных в Московской области |
|
ИНН |
7703363868 |
7703363868 |
|
КПП |
772501001 |
772501001 |
|
Получатель |
УФК по г. |
УФК по Московской области (для ГУ-Отделения ПФР по г. Москве и Московской области) |
|
Банк получателя |
ГУ Банка России по ЦФО |
ГУ Банка России по ЦФО |
|
БИК |
044525000 |
044525000 |
|
Счет |
40101810045250010041 |
40101810845250010102 |
|
ОКТМО |
45915000 |
46000000 (или другой ОКТМО относящийся к территории Московской области) |
|
КБК |
392 1 16 07090 06 0000 140 |
392 1 16 07090 06 0000 140 |
 Москве (для ГУ-Отделения ПФР по г. Москве и Московской области)
Москве (для ГУ-Отделения ПФР по г. Москве и Московской области)
2. Банковские реквизиты для уплаты с 01.01.2020 года должностными лицами организаций финансовых санкций, предусмотренных статьей 15.33.2 КоАП РФ
Банковские реквизиты для уплаты с 01.01.2020 года должностными лицами организаций финансовых санкций, предусмотренных статьей 15.33.2 КоАП РФ
|
Наименование банковского реквизита |
Для должностных лиц организаций, зарегистрированных в г. Москве |
Для должностных лиц организаций, зарегистрированных в Московской области |
|
ИНН |
7703363868 |
7703363868 |
|
КПП |
772501001 |
772501001 |
|
Получатель |
УФК по г. |
УФК по Московской области (для ГУ-Отделения ПФР по г. Москве и Московской области) |
|
Банк получателя |
ГУ Банка России по ЦФО |
ГУ Банка России по ЦФО |
|
БИК |
044525000 |
044525000 |
|
Счет |
40101810045250010041 |
40101810845250010102 |
|
ОКТМО |
45915000 |
46000000 (или другой ОКТМО относящийся к территории Московской области) |
|
КБК |
392 1 16 01151 01 9000 140 |
392 1 16 01151 01 9000 140 |
 Москве (для ГУ-Отделения ПФР по г. Москве и Московской области)
Москве (для ГУ-Отделения ПФР по г. Москве и Московской области)
3.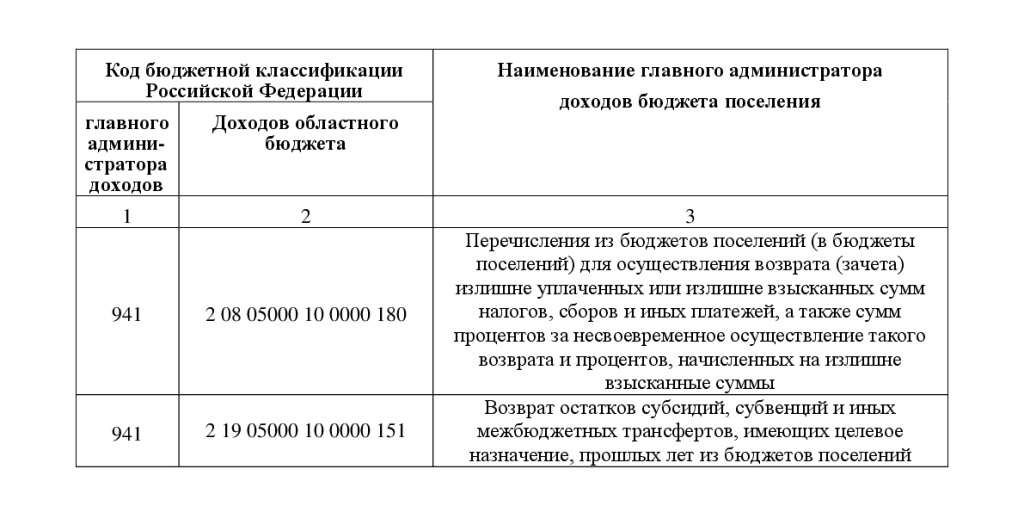 Банковские реквизиты для уплаты с 01.01.2020 года страхователями финансовых санкций, предусмотренных статьями 48-51 Федерального закона от 24.07.2009 № 212-ФЗ «О страховых взносах в Пенсионный фонд Российской Федерации, Фонд социального страхования Российской Федерации, Федеральный фонд обязательного медицинского страхования»
Банковские реквизиты для уплаты с 01.01.2020 года страхователями финансовых санкций, предусмотренных статьями 48-51 Федерального закона от 24.07.2009 № 212-ФЗ «О страховых взносах в Пенсионный фонд Российской Федерации, Фонд социального страхования Российской Федерации, Федеральный фонд обязательного медицинского страхования»
|
Наименование банковского реквизита |
Для страхователей, зарегистрированных в г. Москве |
Для страхователей, зарегистрированных в Московской области |
|
ИНН |
7703363868 |
7703363868 |
|
КПП |
772501001 |
772501001 |
|
Получатель |
УФК по г. |
УФК по Московской области (для ГУ-Отделения ПФР по г. Москве и Московской области) |
|
Банк получателя |
ГУ Банка России по ЦФО |
ГУ Банка России по ЦФО |
|
БИК |
044525000 |
044525000 |
|
Счет |
40101810045250010041 |
40101810845250010102 |
|
ОКТМО |
45915000 |
46000000 (или другой ОКТМО относящийся к территории Московской области) |
|
КБК |
392 1 09 12000 06 0000 140 |
392 1 09 12000 06 0000 140 |
 Москве (для ГУ-Отделения ПФР по г. Москве и Московской области)
Москве (для ГУ-Отделения ПФР по г. Москве и Московской области)
Контактны телефоны: Московская область – 8(4962)67-84-04, 8(496)242-72-30
Читайте также
Новая структура КБК.
 Как сформировать рабочий план счетов?
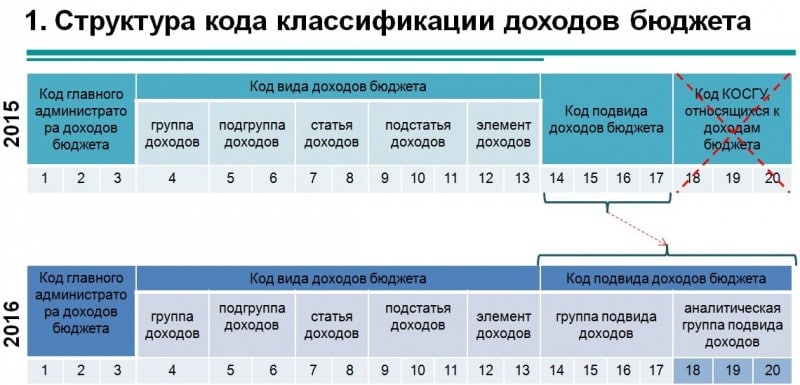
Как сформировать рабочий план счетов?С 1 января 2016 г. изменилась структура кода бюджетной классификации: из неё исключена КОСГУ (классификация операций сектора государственного управления ). При составлении и исполнении бюджетов она больше не применяется. Вместе с тем, КОСГУ продолжает использоваться для ведения бухучёта, составления бухгалтерской и иной финансовой отчётности.
Код бюджетной классификации включается в номер счёта Рабочего плана счетов, поэтому многих бухгалтеров интересует вопрос — как теперь будет выглядеть счёт? Нужно ли переносить остатки на новые счета? И главное, как это всё реализовано в программе «1С:Бухгалтерия государственного учреждения 8»?
На сайте www.buh.ru опубликована статья, в которой методисты 1С подробно рассказывают о новациях бюджетного законодательства и формировании в программе «1С:Бухгалтерия государственного учреждения 8» Рабочего плана счетов для ведения учёта в 2016 г. Предлагаем вашему вниманию краткий обзор этого материала.
Первый раздел статьи посвящён бюджетной классификации 2016 года. Со ссылкой на Федеральный закон от 22.10.2014 № 311-ФЗ и Приказы Минфина № 90н и № 190н приводится актуальная классификация доходов бюджета, источников финансирования дефицитов бюджета, расходов бюджета. Соответствующие изменения внесены в справочники, содержащие бюджетные классификаторы, типовых конфигураций программы 1С:БГУ 8”, Редакции 1, начиная с релиза 1.0.38.2 и Редакции 2, начиная с релиза 2.0.40.5.
Во втором разделе материала опубликован ответ на главный вопрос : «Как сформировать рабочий план счетов в программе?»
Порядок включения бюджетной классификации в номер счёта бухгалтерского учёта регламентирован пунктом 3.2 приказа Минфина России от 06.08.2015 № 124н, вступившим в силу 1 января 2016 года.
С 01.01.2016 в качестве аналитического кода по классификационному признаку поступлений и выбытий (КПС) (разряды 1 — 17 номера счета бюджетного учёта), учреждения указывают 4 — 20 разряд кода классификации доходов бюджетов, расходов бюджетов, источников финансирования дефицитов бюджетов. В 24 — 26 разрядах номера счета Рабочего плана счетов указываются коды классификации операций сектора государственного управления (КОСГУ). Соответствующие изменения внесены в справочник «Классификационные признаки счетов (КПС)», использующийся в программе «1С:Бухгалтерия государственного учреждения 8».
В 24 — 26 разрядах номера счета Рабочего плана счетов указываются коды классификации операций сектора государственного управления (КОСГУ). Соответствующие изменения внесены в справочник «Классификационные признаки счетов (КПС)», использующийся в программе «1С:Бухгалтерия государственного учреждения 8».
Методисты 1С обращают внимание на два важных момента:
1 — с 01.01.2016 г. код главы более не включается в КПС и в номер счета Рабочего плана счетов бюджетного учёта.
2 — Изменение структуры номеров счетов требует создания новых классификационных признаков счетов (элементов справочника Классификационные признаки счетов (КПС) со структурой, применяющейся с 2016 года в части доходов, расходов, источников финансирования дефицитов бюджетов.
В программе «1С:Бухгалтерия государственного учреждения 8» изменён порядок заполнения реквизитов справочника «Классификационные признаки счетов (КПС)». Для элементов справочника с видом КПС «КРБ», «КДБ», «КИФ», дата начала действия которых позднее 01. 01.2016, реквизиты заполняются в соответствии со структурой бюджетных классификаторов, действующей с 2016 года. Для элементов справочника «Классификационные признаки счетов (КПС)» с датой начала действия ранее 01.01.2016 г. состав и порядок заполнения реквизитов соответствует структуре бюджетных классификаторов 2015 года. Порядок и способ использования справочника «Классификационные признаки счетов» — прежние.
01.2016, реквизиты заполняются в соответствии со структурой бюджетных классификаторов, действующей с 2016 года. Для элементов справочника «Классификационные признаки счетов (КПС)» с датой начала действия ранее 01.01.2016 г. состав и порядок заполнения реквизитов соответствует структуре бюджетных классификаторов 2015 года. Порядок и способ использования справочника «Классификационные признаки счетов» — прежние.
Теперь перейдём непосредственно к формированию Рабочего плана счетов бюджетными и автономными учреждениями.
С 1 января 2016 г. бюджетные и автономные учреждения обязаны вести учёт расходов в соответствии с классификацией Видов расходов. При формировании номера счета Рабочего плана счетов бюджетного (автономного) учреждения следует указывать вид расходов не только по счетам учёта санкционирования расходов 500 00 и кассовых расходов 17, 18, но и по счетам 206 00, 208 00, 302 00, 303 00, 109 00, 401 20, и т.п. в разрядах 15-17 номера счёта.
Что нужно сделать для формирования в программе «1С:БГУ 8» номеров счетов с такой структурой?
1. В Учётной политике бюджетного (автономного) учреждения на дату «01.01.2016» укажите соответствующую Структуру Рабочего плана счетов (реквизит «Структура РПС» формы «Учётная политика учреждения»), в которой для каждого КФО установлен тип КПС «Бюджетная классификация». Обратите внимание, что не следует вносить изменения в установленную для учреждения Структуру РПС. Если в установленной в учётной политике учреждения Структуре РПС изменить тип КПС на «Бюджетная классификация», применение произвольного КПС у счетов будет невозможно!
В Учётной политике бюджетного (автономного) учреждения на дату «01.01.2016» укажите соответствующую Структуру Рабочего плана счетов (реквизит «Структура РПС» формы «Учётная политика учреждения»), в которой для каждого КФО установлен тип КПС «Бюджетная классификация». Обратите внимание, что не следует вносить изменения в установленную для учреждения Структуру РПС. Если в установленной в учётной политике учреждения Структуре РПС изменить тип КПС на «Бюджетная классификация», применение произвольного КПС у счетов будет невозможно!
2. Ввести на 01.01.2016 новую Структуру Рабочего плана счетов, в которой для всех КФО указать тип КПС «Бюджетная классификация» и установить её для учреждения с 01.01.2016. Это позволит оформлять документы по двум типам КПС:
– документы с датой до 01.01.2016 можно будет оформлять по КПС с типом «Произвольный»;
– документы с датой после 31.12.2015 можно будет оформлять по КПС с типом «Бюджетная классификация».
Полную версию материала вы найдёте по ссылке: http://buh.ru/articles/documents/46315/.
Как узнать КБК организации по ИНН или ОКТМО
В статье дана краткая характеристика кодов бюджетной классификации и определение структуры шифра. Если вы хотите понять, как узнать КБК организации по ИНН и ОКТМО, то скажем сразу, что это невозможно: эти понятия никак не связаны между собой. Однако можно найти КБК онлайн — подробная инструкция дана в соответствующем пункте.
Любые финансовые операции, совершенные организацией, отражают в платежных поручениях при отправке средств. Делая взносы или оплачивая налоговые суммы, плательщик указывает в платежке тип оплаты, зашифрованный под аббревиатурой КБК.
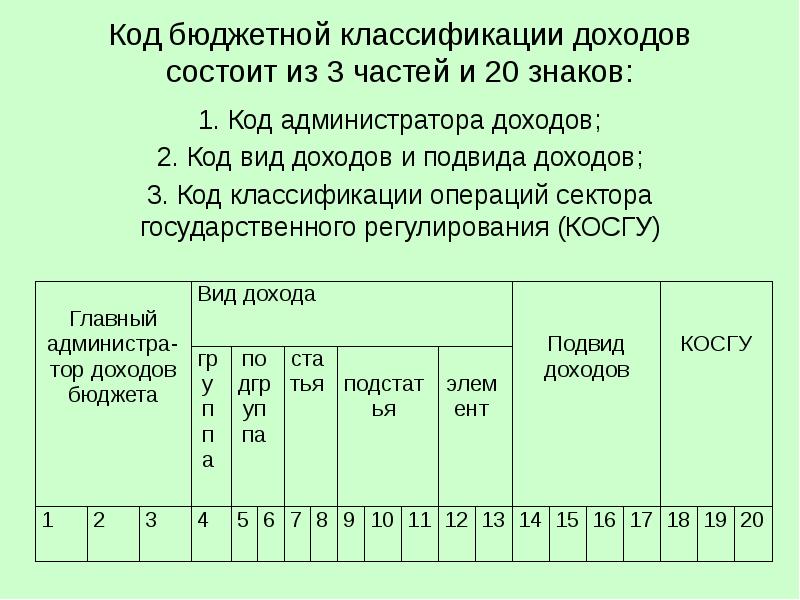
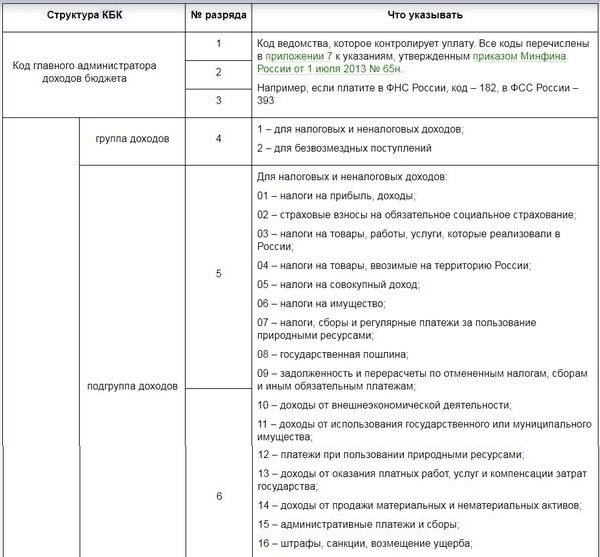
Структура кода
Согласно ст. 1 Приказа Минфина России № 65н от 01.07.2013 (ред. 26.11.2018), коды бюджетной классификации (КБК) — комбинация из 20 цифр, которые отражают тип платежа. Соответственно, код нужен для перечисления средств за необходимую операцию. Если указать неверный шифр, то платеж останется невыясненным и не засчитается за уплату, например, штрафа или очередной суммы сбора.
Цифры разделены на три блока, каждый охватывает по несколько комбинаций. Блоки:
- Первый — шифр главного распределителя денег из бюджета. Он всегда начинается с числа 182 (ст. 2 гл. 2 Приказа Минфина № 65н).
- Второй — код типа прибыли (ст. 3 гл. 2 Приказа Минфина № 65н), который содержит пять подразделов:
- группа прибыли, которая нумеруется единичной цифрой;
- подгруппа прибыли, состоящая из двухзначного числа;
- статья доходов нумеруется двумя единичными символами;
- подстатья доходов содержит три цифры;
- элемент прибыли состоит из двухзначного числа.
- Третий — закодированные подтипы прибыли в бюджет (ст. 4 (1) гл. 2 Приказа Минфина № 65н), который состоит из двух подразделов:
- группа подтипа прибыли, содержащая четыре цифровых символа: 1000, 2000, 3000 или 4000;
- аналитическая группа подтипов дохода в бюджет содержит три числовых значения.
Также законодательство РФ в Приказе Минфина № 65н отдельно классифицирует поступления (гл.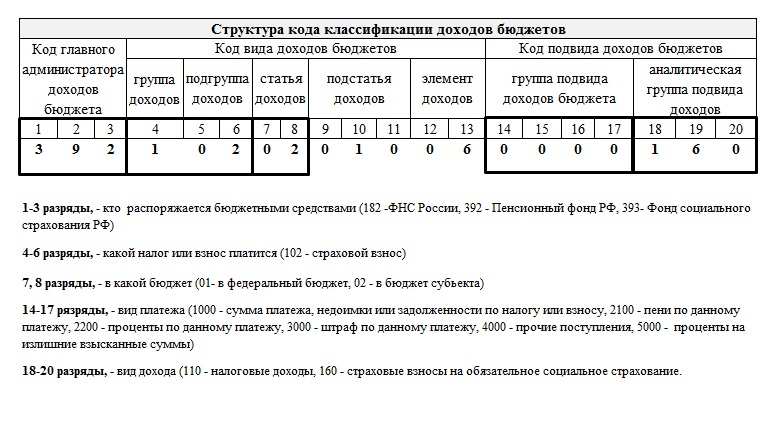 II), расходы (гл. III), операции сектора госуправления (гл. V) и источники, которые финансируют дефицит бюджета (гл. IV). Комбинация чисел для остальных КБК разная, соответственно, шифры тоже разнятся.
II), расходы (гл. III), операции сектора госуправления (гл. V) и источники, которые финансируют дефицит бюджета (гл. IV). Комбинация чисел для остальных КБК разная, соответственно, шифры тоже разнятся.
Поиск КБК
Код бюджетной классификации — шифровка, которая не зависит от индивидуального номера плательщика или муниципального образования. Коды представлены на официальных ресурсах: сайт ФНС России или в Приказе Минфина России № 65н. При заполнении платежки онлайн сервисы проставляют коды автоматически.
По ИНН
КБК по ИНН узнать онлайн невозможно, так как эти два понятия не связаны между собой. Коды бюджетной классифицирует Министерство финансов РФ, а средства поступают в налоговый бюджет. Если сравнить структуру кода и ИНН, то очевидно, что никакую информацию индивидуальный номер плательщика сборов не может дать. По ИНН можно уточнить ОГРН, номер ФНС, к которой прикреплен гражданин, либо КПП плательщика.
По ОКТМО
ОКТМО — общероссийская классификация территориальных муниципальных образований, регламентируемая службой статистики, которая нумерует классификатор ОК 033-2013.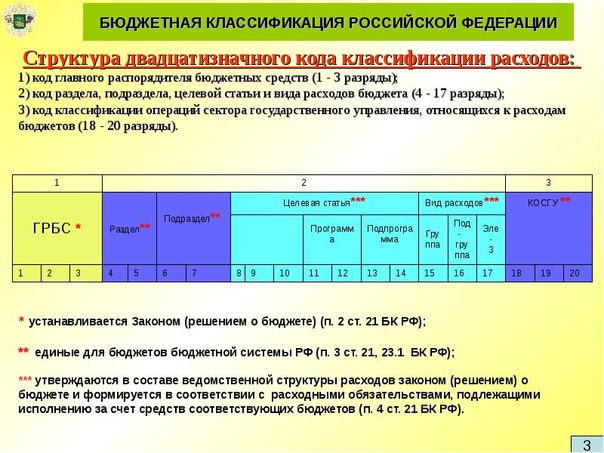 Шифр содержит 8 или 11 цифр, где первые 8 числовых символа — муниципальные образования, а оставшиеся — населенные пункты. Административные центры и города зашифрованы таким способом, чтобы ФНС, куда поступают деньги, знала, в каком регионе находится плательщик. Проще говоря, код по ОКТМО означает регион страны, поэтому КБК и ОКТМО не взаимосвязаны, и по шифру муниципальных образований тип платежа уточнить невозможно.
Шифр содержит 8 или 11 цифр, где первые 8 числовых символа — муниципальные образования, а оставшиеся — населенные пункты. Административные центры и города зашифрованы таким способом, чтобы ФНС, куда поступают деньги, знала, в каком регионе находится плательщик. Проще говоря, код по ОКТМО означает регион страны, поэтому КБК и ОКТМО не взаимосвязаны, и по шифру муниципальных образований тип платежа уточнить невозможно.
Как узнать КБК организации онлайн
Действующую комбинацию бюджетных поступлений или расходов возможно узнать онлайн только на порталах, содержащих официальную правовую документацию:
или на ресурсе ФНС. Чтобы уточнить информацию на портале налоговиков, нужно:
1. Пройти по ссылке.
2. Выбрать категорию плательщика: индивидуальный предприниматель, юридическое или физическое лицо.
3. Выбрать налог или пошлину, за которую вносится оплата.
4. Выбрать тип дохода, а напротив названия будет 20-значный код бюджетной классификации.
При заполнении платежки в банке можно уточнить сведения у сотрудника банковского учреждения.
Центры «Мои Документы» Липецкой области
2015-02-18
Изменение реквизитов для уплаты государственной пошлины
Уважаемые заявители!
Информируем Вас, что в соответствии с приказом Министерства финансов Российской Федерации от 16 декабря 2014 г. № 150н «О внесении изменений в Указания о порядке применения бюджетной классификации Российской Федерации, утвержденные приказом Министерства финансов Российской Федерации от 1 июля 2013 г. № 65н» с 01.01.2015 г. при предоставлении услуг через многофункциональные центры уплата государственной пошлины осуществляется по соответствующим кодам бюджетной классификации с применением новых кодов подвида доходов бюджетов.
В связи с этим просим при заполнении платежных документов на уплату государственной пошлины при обращении через многофункциональные центры предоставления государственных и муниципальных услуг указывать следующие реквизиты.
Реквизиты для уплаты государственной пошлины за выдачу паспорта гражданина РФ, за выдачу паспорта гражданина Российской Федерации взамен утраченного или пришедшего в негодность с 01.01.2015 г. при обращении через многофункциональные центры:
Получатель: УФК по Липецкой области (УФМС России по Липецкой области)
ИНН 4826048892 КПП 482301001
р/с 40101810200000010006 в Отделении Липецк г. Липецк
БИК 044206001
ОКТМО указывается по принадлежности к территории, где была начислена госпошлина (см. ниже классификатор)
КБК (код) — в соответствии с перечнем оказываемых услуг (см. ниже)
Перечень КБК
19210807100018034110 — государственная пошлина за выдачу паспорта гражданина Российской Федерации
19210807100018035110 — государственная пошлина за выдачу паспорта гражданина Российской Федерации взамен утраченного или пришедшего в негодность
Реквизиты для уплаты государственной пошлины за загранпаспорт с 01.01.2015 г. при обращении через многофункциональные центры:
при обращении через многофункциональные центры:
Получатель: УФК по Липецкой области (УФМС России по Липецкой области)
ИНН 4826048892 КПП 482301001
р/с 40101810200000010006 в Отделении Липецк г. Липецк
БИК 044206001
ОКТМО 42701000 (единый для всех районов)
КБК (код) — в соответствии с перечнем оказываемых услуг (см. ниже)
Перечень КБК
19210806000018003110 — государственная пошлина за выдачу паспорта, удостоверяющего личность гражданина Российской Федерации за пределами территории Российской Федерации
19210806000018005110 — государственная пошлина за выдачу паспорта, удостоверяющего личность гражданина Российской Федерации за пределами территории Российской Федерации, гражданину Российской Федерации в возрасте до 14 лет
Реквизиты для уплаты государственной пошлины за государственную регистрацию прав, ограничений (обременений) прав на недвижимое имущество и сделок с ним с 01.01.2015 г., при обращении через многофункциональные центры:
Получатель — УФК по Липецкой области (Управление Росреестра по Липецкой области)
ИНН получателя — 4826044672
КПП получателя — 482601001
Счет получателя — 40101810200000010006
Получатель — Отделение Липецк г. Липецк
Липецк
БИК банка получателя – 044206001
КБК – 32110807020018000110
ОКТМО указывается в платежном документе в соответствии с местом совершения регистрационного действия(см. ниже классификатор)
Назначение платежа: Страховой номер индивидуального лицевого счета плательщика (СНИЛС)* Госпошлина за государственную регистрацию (наименование объекта, адрес). Без НДС.
*Страховой номер индивидуального лицевого счета плательщика (СНИЛС) в назначении платежа указывают только физические лица.
CBC: ассоциативный классификатор с небольшим количеством правил
Андреа Эспозито, 1 Елена Казираги, 2 Франческа Кьяравильо, 1 Алиса Скарабелли, 3 Эльвира Стеллато, 3 Гвидо Пленсич, 3 Джулия Ластелла, 1 Летиция Ди Меглио, 3 Стефано Фуско, 3 Emanuele Avola, 3 Alessandro Jachetti, 4 Caterina Giannitto, 5 Dario Malchiodi, 2 Marco Frasca, 2 Afshin Beheshti, 6,7 Peter N Robinson, 8,9 Giorgio Valentini, 2 Laura Forzenigo, 1 Gianpaolo Carrafiello1 1 Радиологический фонд IRCC Госпиталь Maggiore Policlinico, Милан, 20122, Италия; 2Anacleto Lab, факультет компьютерных наук, Миланский университет, Милан, 20133, Италия; 3Аспирантура диагностической и интервенционной радиологии, Миланский университет, Милан, 20122, Италия; 4Отделение неотложной помощи, Больница поликлиники Больницы Маджоре Фонда IRCCS, Милан, 20122, Италия; 5Радиологическое отделение, Исследовательская больница Humanitas, Милан, 20013, Италия; 6KBR, Отдел космических биологических наук, Исследовательский центр Эймса НАСА, Моффетт Филд, Калифорния, 94035, США; 7 Центр психиатрических исследований Стэнли, Институт Броуда Массачусетского технологического института и Гарвард, Кембридж, Массачусетс, 02142, США; 8 Лаборатория геномной медицины Джексона, Фармингтон, Коннектикут, 06032, США; 9Институт системной геномики Университета Коннектикута, Фармингтон, Коннектикут, 06030, США, для переписки: Эльвира Стеллато; Алиса Скарабелли. Электронное письмо Эльвире[email protected]; [email protected] Цель: определить эффективность системы оценки степени тяжести рентгенограммы грудной клетки (CXR) в сочетании с клиническими и лабораторными данными при прогнозировании исхода у пациентов с COVID-19. Материалы и методы: мы ретроспективно включили 301 пациента, у которых был обратный Положительные результаты транскриптаза-полимеразной цепной реакции (ОТ-ПЦР) на COVID-19. Были собраны рентгенограммы, клинические и лабораторные данные. Была определена система оценки степени тяжести рентгенологического рентгенологического исследования, основанная на качественной оценке двух профессиональных торакальных рентгенологов.В зависимости от клинического исхода пациенты были разделены на два класса: умеренные / легкие (пациенты, которые не умерли или не были интубированы) и тяжелые (пациенты, которые были интубированы и / или умерли). Анализ кривой ROC был применен, чтобы определить точку отсечения, максимизирующую индекс Юдена при прогнозировании результата.
Электронное письмо Эльвире[email protected]; [email protected] Цель: определить эффективность системы оценки степени тяжести рентгенограммы грудной клетки (CXR) в сочетании с клиническими и лабораторными данными при прогнозировании исхода у пациентов с COVID-19. Материалы и методы: мы ретроспективно включили 301 пациента, у которых был обратный Положительные результаты транскриптаза-полимеразной цепной реакции (ОТ-ПЦР) на COVID-19. Были собраны рентгенограммы, клинические и лабораторные данные. Была определена система оценки степени тяжести рентгенологического рентгенологического исследования, основанная на качественной оценке двух профессиональных торакальных рентгенологов.В зависимости от клинического исхода пациенты были разделены на два класса: умеренные / легкие (пациенты, которые не умерли или не были интубированы) и тяжелые (пациенты, которые были интубированы и / или умерли). Анализ кривой ROC был применен, чтобы определить точку отсечения, максимизирующую индекс Юдена при прогнозировании результата. Клинические и лабораторные данные были проанализированы с помощью классификаторов Boruta и Random Forest. Результаты: Согласие между двумя оценками радиологов было существенным (каппа = 0,76). Радиологический балл ≥ 9 предсказывает тяжелый класс: чувствительность = 0.67, специфичность = 0,58, точность = 0,61, PPV = 0,40, NPV = 0,81, оценка F1 = 0,50, AUC = 0,65. Такие показатели были улучшены до чувствительности = 0,80, специфичности = 0,86, точности = 0,84, PPV = 0,73, NPV = 0,90, балла F1 = 0,76, AUC = 0,82, сочетая две клинические переменные (сатурацию кислорода [SpO2]), соотношение артериальных парциальное давление кислорода к фракционному вдыхаемому кислороду [соотношение P / F] и результаты трех лабораторных тестов (C-реактивный белок, лимфоциты [%], гемоглобин). Заключение: наша оценка тяжести CXR, присвоенная двумя радиологами, которые читали CXR в сочетании с некоторые конкретные клинические данные и лабораторные результаты могут сыграть потенциальную роль в прогнозировании исхода у пациентов с COVID-19.
Клинические и лабораторные данные были проанализированы с помощью классификаторов Boruta и Random Forest. Результаты: Согласие между двумя оценками радиологов было существенным (каппа = 0,76). Радиологический балл ≥ 9 предсказывает тяжелый класс: чувствительность = 0.67, специфичность = 0,58, точность = 0,61, PPV = 0,40, NPV = 0,81, оценка F1 = 0,50, AUC = 0,65. Такие показатели были улучшены до чувствительности = 0,80, специфичности = 0,86, точности = 0,84, PPV = 0,73, NPV = 0,90, балла F1 = 0,76, AUC = 0,82, сочетая две клинические переменные (сатурацию кислорода [SpO2]), соотношение артериальных парциальное давление кислорода к фракционному вдыхаемому кислороду [соотношение P / F] и результаты трех лабораторных тестов (C-реактивный белок, лимфоциты [%], гемоглобин). Заключение: наша оценка тяжести CXR, присвоенная двумя радиологами, которые читали CXR в сочетании с некоторые конкретные клинические данные и лабораторные результаты могут сыграть потенциальную роль в прогнозировании исхода у пациентов с COVID-19. Ключевые слова: рентгенография, грудная клетка, COVID-19, искусственный интеллект, прогноз
Ключевые слова: рентгенография, грудная клетка, COVID-19, искусственный интеллект, прогноз
Ассоциативный классификатор с небольшим количеством правил — Университет штата Аризона
TY — JOUR
T1 — CBC
T2 — Ассоциативный классификатор с небольшим числом правил
AU — Deng, Houtao
AU — Runger, George
AU — Tuv, Eugene
AU — Bannister, Wade
N1 — Информация о финансировании: Работа частично поддержана грантом ONR N00014-09-1-0656.Авторские права: Copyright 2014 Elsevier B.V., Все права защищены.
PY — 2014/3
Y1 — 2014/3
N2 — Ассоциативные классификаторы были предложены для получения точной модели с возможностью интерпретации каждого отдельного правила. Однако существующие ассоциативные классификаторы часто состоят из большого количества правил, и поэтому их трудно интерпретировать. Мы показываем, что ассоциативные классификаторы, состоящие из упорядоченного набора правил, могут быть представлены в виде древовидной модели.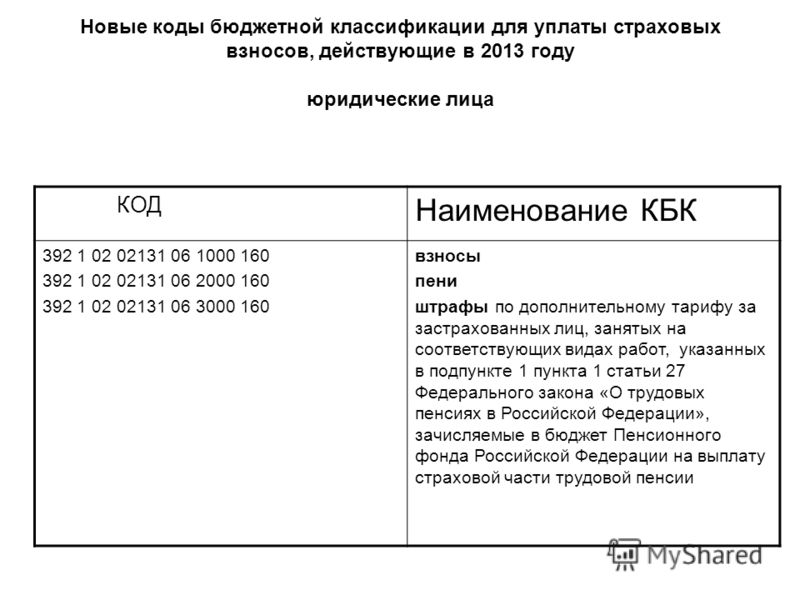 С этой точки зрения ясно, что эти классификаторы ограничены тем, что по крайней мере один дочерний узел нелистового узла никогда не разделяется.Мы предлагаем новую модель дерева, то есть дерево на основе условий (CBT), чтобы ослабить ограничение. Кроме того, мы также предлагаем алгоритм преобразования CBT в упорядоченный набор правил с краткими условиями правил. Этот упорядоченный набор правил называется классификатором на основе условий (CBC). Таким образом, интерпретируемость ассоциативного классификатора сохраняется, но возможны более выразительные модели. Алгоритм преобразования правил также может применяться к обычным двоичным деревьям решений для извлечения упорядоченного набора правил с простыми условиями правила.Выбор функций применяется к двоичному представлению условий для дальнейшего упрощения / улучшения моделей. Экспериментальные исследования показывают, что CBC имеет конкурентные показатели точности и имеет значительно меньшее количество правил (медиана 10 правил на набор данных), чем известные ассоциативные классификаторы, такие как CBA (медиана 47) и GARC (медиана 21).
С этой точки зрения ясно, что эти классификаторы ограничены тем, что по крайней мере один дочерний узел нелистового узла никогда не разделяется.Мы предлагаем новую модель дерева, то есть дерево на основе условий (CBT), чтобы ослабить ограничение. Кроме того, мы также предлагаем алгоритм преобразования CBT в упорядоченный набор правил с краткими условиями правил. Этот упорядоченный набор правил называется классификатором на основе условий (CBC). Таким образом, интерпретируемость ассоциативного классификатора сохраняется, но возможны более выразительные модели. Алгоритм преобразования правил также может применяться к обычным двоичным деревьям решений для извлечения упорядоченного набора правил с простыми условиями правила.Выбор функций применяется к двоичному представлению условий для дальнейшего упрощения / улучшения моделей. Экспериментальные исследования показывают, что CBC имеет конкурентные показатели точности и имеет значительно меньшее количество правил (медиана 10 правил на набор данных), чем известные ассоциативные классификаторы, такие как CBA (медиана 47) и GARC (медиана 21). CBC с выбором функций имеет еще меньшее количество правил.
CBC с выбором функций имеет еще меньшее количество правил.
AB — Ассоциативные классификаторы были предложены для получения точной модели с возможностью интерпретации каждого отдельного правила.Однако существующие ассоциативные классификаторы часто состоят из большого количества правил, и поэтому их трудно интерпретировать. Мы показываем, что ассоциативные классификаторы, состоящие из упорядоченного набора правил, могут быть представлены в виде древовидной модели. С этой точки зрения ясно, что эти классификаторы ограничены тем, что по крайней мере один дочерний узел нелистового узла никогда не разделяется. Мы предлагаем новую модель дерева, то есть дерево на основе условий (CBT), чтобы ослабить ограничение. Кроме того, мы также предлагаем алгоритм преобразования CBT в упорядоченный набор правил с краткими условиями правил.Этот упорядоченный набор правил называется классификатором на основе условий (CBC). Таким образом, интерпретируемость ассоциативного классификатора сохраняется, но возможны более выразительные модели. Алгоритм преобразования правил также может применяться к обычным двоичным деревьям решений для извлечения упорядоченного набора правил с простыми условиями правила. Выбор функций применяется к двоичному представлению условий для дальнейшего упрощения / улучшения моделей. Экспериментальные исследования показывают, что CBC имеет конкурентные показатели точности и имеет значительно меньшее количество правил (медиана 10 правил на набор данных), чем известные ассоциативные классификаторы, такие как CBA (медиана 47) и GARC (медиана 21).CBC с выбором функций имеет еще меньшее количество правил.
Алгоритм преобразования правил также может применяться к обычным двоичным деревьям решений для извлечения упорядоченного набора правил с простыми условиями правила. Выбор функций применяется к двоичному представлению условий для дальнейшего упрощения / улучшения моделей. Экспериментальные исследования показывают, что CBC имеет конкурентные показатели точности и имеет значительно меньшее количество правил (медиана 10 правил на набор данных), чем известные ассоциативные классификаторы, такие как CBA (медиана 47) и GARC (медиана 21).CBC с выбором функций имеет еще меньшее количество правил.
кВт — правило ассоциации
кВт — дерево решений
кВт — выбор функций
кВт — сокращение правил
кВт — классификатор на основе правил
UR — http://www.scopus.com/inward/record. url? scp = 84897654160 & partnerID = 8YFLogxK
UR — http://www.scopus.com/inward/citedby.url?scp=84897654160&partnerID=8YFLogxK
U2 — 10.1016 / j.dss.2013 9.110002 DO 9000. 004 DO 9000.004 .1016 / j.dss.2013.11.004
004 DO 9000.004 .1016 / j.dss.2013.11.004
M3 — Статья
AN — SCOPUS: 84897654160
VL — 59
SP — 163
EP — 170
JO — Системы поддержки принятия решений
JF — Системы поддержки принятия решений
SN — 0167-9236
IS — 1
ER —
Code-Bridged Classifier (CBC): защита с низкими или отрицательными накладными расходами для обеспечения устойчивости классификатора CNN к враждебным атакам
Использование DAE для уточнения возмущенных входных выборок перед их подачей в классификатор является типичным механизмом защиты от злонамеренных примеров. [2, 12] .Общий вид такой защиты показан на рис. 5. (вверху). На этом рисунке φ (.), Ζ (.) — декодер и кодер DAE, соответственно, φ ′ (.) — первые несколько уровней CONV классификатора CNN, а C (.) — более поздние этапы CONV. . В этой защите отдельно обучаются DAE и CNN. DAE обучается минимизировать ошибку восстановления, в то время как CNN обучается уменьшать заранее заданную функцию потерь (например, потери L1 или L2). Улучшенная версия такой защиты — это когда обучение выполняется последовательно, где на первом этапе обучается DAE, а затем классификатор CNN обучается с использованием выходных данных DAE в качестве входной выборки.Обратите внимание, что второе решение имеет тенденцию к более высокой точности классификации. Независимо от выбора обучения добавление DAE к классификатору CNN увеличивает его сложность. Помимо дополнительной вычислительной сложности, проблема с этим защитным механизмом состоит в том, что АЕ могут действовать как двойной агент: с одной стороны, уточнение состязательных примеров является эффективным средством удаления состязательного возмущения (шума) из входного изображения и является надежной защитой. механизм, но, с другой стороны, его ошибка реконструкции ER может вызвать неправильную классификацию чистых входных изображений.Для исправления поведения DAE мы предлагаем концепцию классификаторов кодового моста (CBC), направленную на 1) устранение влияния ошибки восстановления лежащей в основе DAE и 2) снижение вычислительной сложности объединенной DAE и классификатора для расширения его применимость.
Улучшенная версия такой защиты — это когда обучение выполняется последовательно, где на первом этапе обучается DAE, а затем классификатор CNN обучается с использованием выходных данных DAE в качестве входной выборки.Обратите внимание, что второе решение имеет тенденцию к более высокой точности классификации. Независимо от выбора обучения добавление DAE к классификатору CNN увеличивает его сложность. Помимо дополнительной вычислительной сложности, проблема с этим защитным механизмом состоит в том, что АЕ могут действовать как двойной агент: с одной стороны, уточнение состязательных примеров является эффективным средством удаления состязательного возмущения (шума) из входного изображения и является надежной защитой. механизм, но, с другой стороны, его ошибка реконструкции ER может вызвать неправильную классификацию чистых входных изображений.Для исправления поведения DAE мы предлагаем концепцию классификаторов кодового моста (CBC), направленную на 1) устранение влияния ошибки восстановления лежащей в основе DAE и 2) снижение вычислительной сложности объединенной DAE и классификатора для расширения его применимость.
Рис. 5. (внизу) иллюстрирует предлагаемое нами решение, в котором кодировщик φ (.) Обученной DAE и часть исходной CNN (C (.)) Объединены, чтобы сформировать гибридную, но сжатую модель. В этой модели декодер ζ (.) DAE и первые несколько слоев CONV модели CNN, φ ′ (.), удаляются. В CBC ζ (.) И φ ′ (.) Исключаются с интуицией, что они действуют как автоматический декодер (AD). В отличие от AE, AD переводит последнее пространство в изображение и обратно в другое скрытое пространство (промежуточное представление изображения в CNN, захваченное выходными каналами φ ‘(.)). Это, однако, проблематично, потому что 1) декодер ζ (.) Не идеален и вносит ошибку восстановления в улучшенное изображение, 2) декодирование и кодирование (первые несколько слоев CONV действуют как кодировщик) изображения только транслируют изображение из одного последнего места в другое, не добавляя к нему никакой информации.Это когда такое преобразование кода (последнее пространство в скрытое пространство) может быть исключено, и код на выходе φ (. ) Может быть напрямую использован для классификации. Это позволяет нам устранить бесполезный AD (декодер ζ (.) И первые несколько сверточных слоев исходной CNN, которые действуют как кодировщики) и не только снизить вычислительную сложность всей модели, но также повысить точность модели за счет устранения шум, связанный с реконструкцией изображения декодера ζ (.).
) Может быть напрямую использован для классификации. Это позволяет нам устранить бесполезный AD (декодер ζ (.) И первые несколько сверточных слоев исходной CNN, которые действуют как кодировщики) и не только снизить вычислительную сложность всей модели, но также повысить точность модели за счет устранения шум, связанный с реконструкцией изображения декодера ζ (.).
Процесс обучения для CBC является последовательным: сначала мы обучаем DAE, секция кодировщика модели отделяется.Затем обученный декодер соединяется с CNN меньшего размера по сравнению с исходной моделью. Один из способов построить меньшую модель — удалить несколько первых слоев CONV исходной модели и настроить ширину DAE и частичного CNN в соответствии с размерами фильтра. Эмпирическое правило для исключения слоев состоит в том, чтобы удалить столько слоев CONV, сколько в кодировщике AE. Следующим шагом является обучение частичной CNN, фиксируя значения декодера, позволяя распространению изменять только веса в классификаторе C (.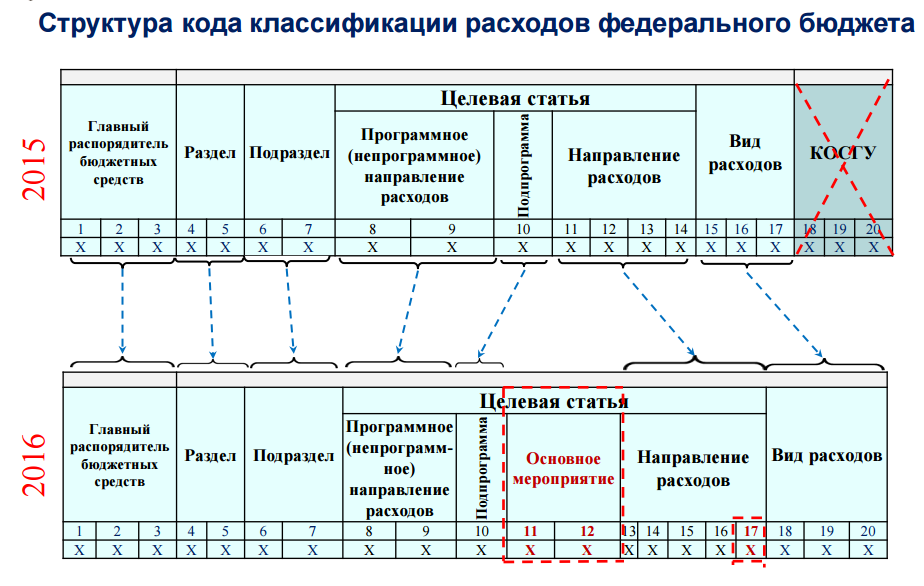 ).
).
на основе статистики кода ASCII
В области информационной безопасности блочный шифр широко используется для защиты сообщений, и его безопасность, естественно, привлекает внимание людей. Идентификация криптосистемы является предпосылкой анализа зашифрованных данных. Он относится к категории анализа атак в криптоанализе и имеет важное теоретическое и прикладное значение. В этой статье основное внимание уделяется извлечению признаков зашифрованного текста и построению классификаторов идентификации криптосистем.Основное содержание и нововведения данной статьи заключаются в следующем. Во-первых, вдохновленные языковой обработкой, мы предлагаем схему извлечения признаков, основанную на статистике шифртекстов ASCII, которая уменьшает размерность предварительной обработки данных. Во-вторых, на основе предыдущей работы мы увеличиваем количество типов блочных шифров до восьми, шифруем открытый текст того же размера, что и экспериментальные объекты, и распознаем криптосистему.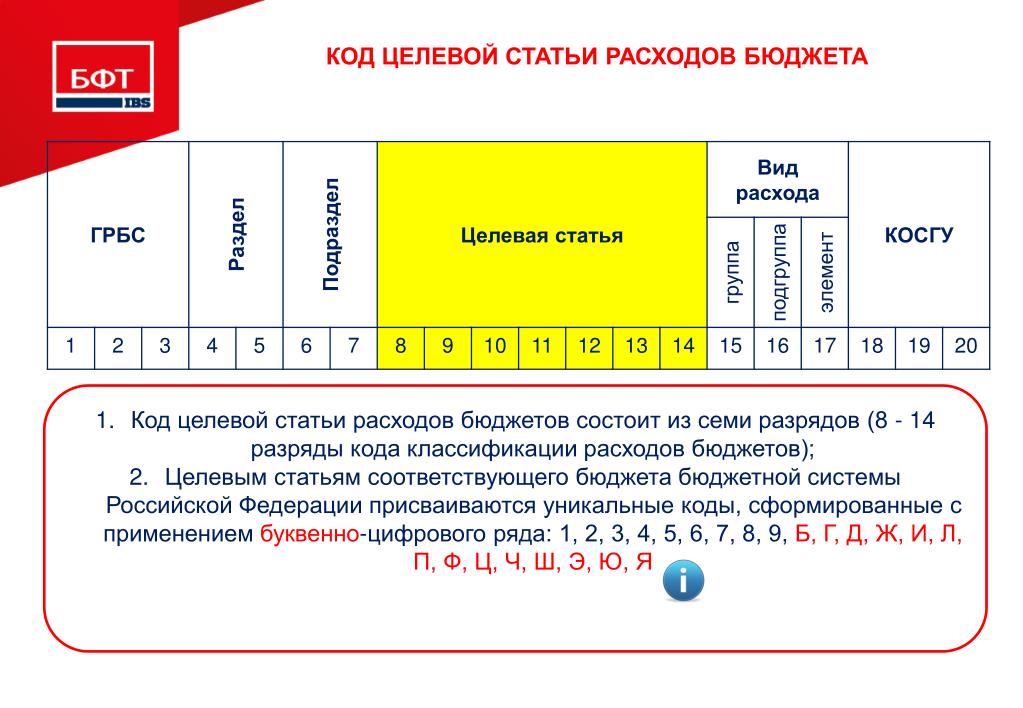 В-третьих, мы используем два классификатора машинного обучения для проведения экспериментов по классификации, включая случайный лес и SVM.Результаты экспериментов показывают, что наша схема может не только повысить точность идентификации 8 типичных алгоритмов блочного шифрования, но также сократить время эксперимента и уменьшить вычислительную нагрузку за счет значительного минимизации размерности вектора признаков. И различные оценочные показатели, полученные с помощью схемы, были значительно улучшены по сравнению с существующей опубликованной литературой.
В-третьих, мы используем два классификатора машинного обучения для проведения экспериментов по классификации, включая случайный лес и SVM.Результаты экспериментов показывают, что наша схема может не только повысить точность идентификации 8 типичных алгоритмов блочного шифрования, но также сократить время эксперимента и уменьшить вычислительную нагрузку за счет значительного минимизации размерности вектора признаков. И различные оценочные показатели, полученные с помощью схемы, были значительно улучшены по сравнению с существующей опубликованной литературой.
1. Введение
С развитием информационной индустрии информационная безопасность постепенно становится важной частью общества.В соответствии с требованиями в различных сложных условиях криптологи разрабатывают ряд алгоритмов шифрования, таких как DES, AES и IDEA. Математическая теория, применяемая в разных криптосистемах, различна. Следовательно, не существует универсального удовлетворительного метода криптоанализа, чтобы исправить все проблемы, встречающиеся при криптоанализе. Большинство практических методов криптоанализа предназначены для определенных криптосистем с определенной структурой. Таким образом, идентификация криптосистемы становится основной задачей криптоанализа, которую следует решать перед анализом определенных криптосистем.В то же время способность противостоять идентификации криптосистемы может использоваться как индикатор для измерения безопасности криптосистемы, который является ценным справочным материалом для проектирования криптосистемы [1]. Криптосистемы, которые могут противостоять различающей атаке, рассматриваются как алгоритм с высокой степенью безопасности. Исследования по идентификации криптосистемы сыграли двоякую роль в продвижении применения криптоанализа и развитии криптографии [2].
Большинство практических методов криптоанализа предназначены для определенных криптосистем с определенной структурой. Таким образом, идентификация криптосистемы становится основной задачей криптоанализа, которую следует решать перед анализом определенных криптосистем.В то же время способность противостоять идентификации криптосистемы может использоваться как индикатор для измерения безопасности криптосистемы, который является ценным справочным материалом для проектирования криптосистемы [1]. Криптосистемы, которые могут противостоять различающей атаке, рассматриваются как алгоритм с высокой степенью безопасности. Исследования по идентификации криптосистемы сыграли двоякую роль в продвижении применения криптоанализа и развитии криптографии [2].
В 2006 году Дилип и Сехар [3] предложили схему распознавания блочного шифра, основанную на машине опорных векторов (SVM) с помощью классификации и подсчета текста.Автор сравнил производительность распознавания SVM и метода K -means и принял мультикриптосистему, включающую вектор документа фиксированной длины и вектор документа переменной длины. В 2008 году Нагиредди [4] рассмотрел распознавание криптосистемы как атаку криптосистемы и распознал пять криптосистем. Было обнаружено, что блочные шифры в режиме ECB легче распознавать.
В 2008 году Нагиредди [4] рассмотрел распознавание криптосистемы как атаку криптосистемы и распознал пять криптосистем. Было обнаружено, что блочные шифры в режиме ECB легче распознавать.
В 2012 году Chou et al. [5] предложила схему классификации на основе машины опорных векторов (SVM), которую можно распознать и классифицировать как два режима работы блочных шифров (CBC и ECB).Эксперимент разработан как индивидуальная классификация с выделением прогресса, которая реализована в трех алгоритмах шифрования (AES, DES и RC4) с 1000 выборками. Результат эксперимента показывает сильную классификационную способность в атаке криптографического распознавания SVM. В 2018 году Ху и Чжао [6] разработали отличительную атаку, основанную на теории дискриминантного анализа Фишера (FDA). В этой работе авторы извлекают 9 видов статистических данных в качестве признака зашифрованного текста, который используется для различения 4 потоковых шифров и 7 блочных шифров в эксперименте по однозначной идентификации. Результат эксперимента показывает, что точность идентификации зашифрованных файлов в режиме ECB может достигать 80%. Точность идентификации потоковых шифров SMS4 из блочных шифров в режиме CBC может достигать 60%.
Результат эксперимента показывает, что точность идентификации зашифрованных файлов в режиме ECB может достигать 80%. Точность идентификации потоковых шифров SMS4 из блочных шифров в режиме CBC может достигать 60%.
В 2018 году Хуанг и др. [7] предложили двухэтапную схему распознавания криптосистемы на основе случайного леса. В этой работе Huang et al. разделите задачу распознавания криптосистемы на 2 последовательные процедуры: «кластерное распознавание» и «единичное распознавание». На первом этапе схема распознает кластер криптосистем, а затем классификатор определяет тип криптосистемы.По сравнению с традиционной одноступенчатой схемой, двухступенчатая схема превосходит 19,55%, 21,40% и 22,99% в отношении точности распознавания в трех рассматриваемых параметрах, соответственно.
В этой статье основной вклад нашей работы организован следующим образом. В разделе 2 мы даем базовое определение идентификации криптосистемы и системное описание схемы идентификации криптосистемы. В разделе 4 мы предлагаем схему идентификации криптосистемы, основанную на статистических характеристиках кода ASCII.В разделе 5 мы рассмотрели влияние нашей схемы выделения признаков в различных режимах работы блочных шифров на экспериментальные результаты. Кроме того, мы увеличиваем количество криптосистем до восьми (AES-128, AES-256, Blowfish-64, Camellia-128, DES, 3DES, IDEA-64 и SMS4-128). Чтобы показать влияние различных классификаторов машинного обучения (машина опорных векторов и случайный лес), мы сравниваем оценку экспериментов с различными экспериментальными показателями, включая точность, отзыв и 1 балл F .
В разделе 4 мы предлагаем схему идентификации криптосистемы, основанную на статистических характеристиках кода ASCII.В разделе 5 мы рассмотрели влияние нашей схемы выделения признаков в различных режимах работы блочных шифров на экспериментальные результаты. Кроме того, мы увеличиваем количество криптосистем до восьми (AES-128, AES-256, Blowfish-64, Camellia-128, DES, 3DES, IDEA-64 и SMS4-128). Чтобы показать влияние различных классификаторов машинного обучения (машина опорных векторов и случайный лес), мы сравниваем оценку экспериментов с различными экспериментальными показателями, включая точность, отзыв и 1 балл F .
2. Предварительные сведения
Чтобы гарантировать безопасность связи и передачи документов, люди часто применяют блочные шифры. Применение блочного шифра стало стандартом в области гарантии конфиденциальности, которая отказывает никому, кроме коммуникатора, в получении информации при передаче. Ниже мы представляем краткое введение в блочный шифр, который необходим для понимания нашей работы.
2.1. Блочный шифр
Как основная часть криптосистемы, блочный шифр широко используется для защиты информации.При секретности документов блочный шифр также применяется в качестве базовой функции, такой как генератор случайных чисел, хэш-функция и цифровая подпись [8]. Чтобы зашифровать содержимое сообщения, открытый текст делится на фиксированную длину, которая называется блоком.
Перед шифрованием блочный шифр разделяет сообщение на группы фиксированной длины. При добавлении сообщения и ключа алгоритм шифрования выводит зашифрованные тексты в группах (), где (a) (b) (c)
Предполагая, что ключ один и тот же, преобразование блочного шифра в любой блок открытого текста не будет отличаться.Следовательно, при исследовании блочного шифра необходимо только изучить закон преобразования любой группы.
Рабочий процесс блочного шифра показан на рисунке 1.
2.2. Два режима работы блочного шифра
Адаптируясь к различным рабочим требованиям, пользователь может выбрать один из нескольких режимов работы блочного шифра. В этой работе мы в основном рассматриваем режим электронной кодовой книги (ECB) и режим цепочки блоков шифров (CBC).
В этой работе мы в основном рассматриваем режим электронной кодовой книги (ECB) и режим цепочки блоков шифров (CBC).
Режим ECB — это краткий метод шифрования, при котором каждый блок открытого текста шифруется отдельно.Применяя ту же операцию для всех блоков (как показано на рисунке 2), процесс шифрования может быть реализован путем параллельных вычислений, требующих, чтобы длина открытого текста в битах была целым кратным блоку [9].
В 1976 году IBM разработала и предложила режим CBC (цепочка блоков шифров), который является улучшением режима ECB в отношении неопределенности шифрования [10]. Вместо того, чтобы напрямую шифровать каждый блок, режим CBC добавляет случайный IV (вектор инициализации) к открытому тексту перед шифрованием и устанавливает предыдущий блок шифрования в качестве следующего IV (как показано на рисунке 3).
3. Теоретические основы идентификации криптосистемы
3.1. Идентификация криптосистемы
Большинство задач идентификации криптосистем, основанных на классификаторах машинного обучения, используют режим контролируемого обучения [11]. Схема может быть представлена в четыре этапа [12]. Сначала выберите объект классификации и идентификации. Во-вторых, извлеките векторы признаков экспериментального объекта. В-третьих, выберите и обучите соответствующий классификатор машинного обучения.Наконец, выполните идентификацию криптосистемы. Однако это описание просто классифицирует идентификацию криптосистемы как проблему идентификации шаблонов, и невозможно провести углубленное исследование особенностей идентификации криптосистемы, поскольку это затрудняет крупный прорыв на техническом уровне.
Схема может быть представлена в четыре этапа [12]. Сначала выберите объект классификации и идентификации. Во-вторых, извлеките векторы признаков экспериментального объекта. В-третьих, выберите и обучите соответствующий классификатор машинного обучения.Наконец, выполните идентификацию криптосистемы. Однако это описание просто классифицирует идентификацию криптосистемы как проблему идентификации шаблонов, и невозможно провести углубленное исследование особенностей идентификации криптосистемы, поскольку это затрудняет крупный прорыв на техническом уровне.
По указанным выше причинам в этом разделе мы даем определение идентификации криптосистемы и схемы идентификации криптосистемы. Результаты схемы оцениваются по критериям оценки идентификационной классификации машинного обучения, а именно: точность, скорость отзыва и 1 балл F .
Определение 1. Рассмотрим набор криптосистем, где n — количество криптосистем. — это зашифрованные тексты, генерируемые криптосистемой в наборе криптосистем. При наличии схемы идентификации криптосистема может быть распознана по определенному показателю оценки в случае, если ее криптосистема неизвестна. Этот процесс называется идентификацией криптосистемы.
При наличии схемы идентификации криптосистема может быть распознана по определенному показателю оценки в случае, если ее криптосистема неизвестна. Этот процесс называется идентификацией криптосистемы.
Экспериментальный индикатор оценки A в приведенном выше определении обычно относится к индикатору оценки классификации машинного обучения, точности, скорости отзыва, F 1 балл и точности, которая немного отличается от точности идентификации при идентификации по образцу [13 ].
Определение 2. Рабочий процесс для идентификации криптосистемы. — это признак, извлеченный из зашифрованных текстов, и применяемый классификатор классификации, а затем тройка отмечается как схема идентификации криптосистемы.
Мы представляем рабочий процесс идентификации криптосистемы в алгоритме 1.
|
3.
 2. Случайный лес
2. Случайный лесСлучайный лес использует метод повторной выборки начальной загрузки для случайного извлечения выборок из исходного набора обучающих выборок, создания нового набора обучающих выборок, а затем создания деревьев классификации на основе набора выборок самообслуживания для формирования случайной выборки. лес. Результат классификации новых данных зависит от оценки, полученной в результате голосования по дереву классификации. Каждое дерево в лесу имеет одинаковое распределение, и ошибка классификации зависит от способности классификации каждого дерева и корреляции между ними.При выборе признаков применяется случайный метод для разделения каждого узла, а затем сравниваются ошибки, сгенерированные в различных ситуациях, и определяется количество признаков путем оценки ошибки, способности классификации и корреляционного анализа [14].
3.3. Машина опорных векторов
Основная теория машины опорных векторов (SVM) состоит в том, чтобы установить оптимальную гиперплоскость решения, чтобы расстояние между двумя типами выборок на двух сторонах плоскости, ближайшей к плоскости, было максимальным. Для многомерного набора выборок модель SVM случайным образом генерирует гиперплоскость и непрерывно перемещается для классификации выборок, пока точки выборки, принадлежащие к разным категориям в обучающей выборке, не будут расположены по обе стороны гиперплоскости. Для одной и той же задачи классификации может существовать несколько разных гиперплоскостей, которые могли бы разделить набор данных с удовлетворительной точностью. Следовательно, модель обучения SVM обладает хорошими возможностями обобщения в задаче классификации.Обеспечивая точность классификации, SVM находит такую гиперплоскость, чтобы максимизировать пустое пространство по обе стороны от гиперплоскости, чтобы достичь оптимальной классификации линейных разделяемых выборок [15].
Для многомерного набора выборок модель SVM случайным образом генерирует гиперплоскость и непрерывно перемещается для классификации выборок, пока точки выборки, принадлежащие к разным категориям в обучающей выборке, не будут расположены по обе стороны гиперплоскости. Для одной и той же задачи классификации может существовать несколько разных гиперплоскостей, которые могли бы разделить набор данных с удовлетворительной точностью. Следовательно, модель обучения SVM обладает хорошими возможностями обобщения в задаче классификации.Обеспечивая точность классификации, SVM находит такую гиперплоскость, чтобы максимизировать пустое пространство по обе стороны от гиперплоскости, чтобы достичь оптимальной классификации линейных разделяемых выборок [15].
4. Схема идентификации криптосистемы на основе статистики кода ASCII
Процесс шифрования данных изображения заключается в преобразовании изображения в массив и сохранении его в базе данных после шифрования base64. Однако в изображении присутствует большое количество пикселей с одинаковым цветом, и распределение пикселей с одинаковым цветом в разных изображениях отличается, что может привести к различиям в распределении кода ASCII зашифрованных данных изображения. Поэтому, основываясь на различии распределения статистических значений кода ASCII в зашифрованных текстах, в сочетании с определением предыдущей схемы идентификации криптосистемы, мы разрабатываем следующую схему идентификации криптосистемы. Программа состоит из двух этапов: этапа обучения и этапа тестирования (как показано на рисунке 4).
Поэтому, основываясь на различии распределения статистических значений кода ASCII в зашифрованных текстах, в сочетании с определением предыдущей схемы идентификации криптосистемы, мы разрабатываем следующую схему идентификации криптосистемы. Программа состоит из двух этапов: этапа обучения и этапа тестирования (как показано на рисунке 4).
4.1. Этап обучения
(1) Соберите набор файлов зашифрованных текстов с известным алгоритмом шифрования. (2) Вычислите частоту всех кодов ASCII в файле зашифрованных текстов и создайте словарь для каждого файла зашифрованного текста.Все коды ASCII и частота их появления являются ключами и значениями словаря. (3) Все значения словаря, полученные из каждого зашифрованного текста, извлекаются как вектор признаков зашифрованных текстов. Поскольку существует 256 расширенных кодов ASCII, векторы признаков, извлеченные из каждого зашифрованного текста, являются 256-мерными. Затем мы получаем набор собственных векторов, которые являются 256-мерными векторами. (4) Категории криптосистем всех файлов зашифрованного текста могут быть представлены в виде -мерного массива размером m ; (FEA, метка) представляет собственный вектор с меткой криптосистемы.Помеченные данные (FEA, метка) вводятся в классификатор для обучения модели классификации.
(4) Категории криптосистем всех файлов зашифрованного текста могут быть представлены в виде -мерного массива размером m ; (FEA, метка) представляет собственный вектор с меткой криптосистемы.Помеченные данные (FEA, метка) вводятся в классификатор для обучения модели классификации.
4.2. Этап тестирования
(1) Извлечение векторов признаков из зашифрованных текстов F для распознавания (2) Введите вектор признаков в обученную модель классификации, и модель выдаст результаты классификации зашифрованных текстов F
В этой работе, мы применяем алгоритм классификации случайных лесов и MLP в качестве классификаторов идентификации криптосистем, которые просты в реализации и имеют небольшие вычислительные затраты.Разнообразие его внутренних основных учащихся обусловлено не только нарушением выборки, но и нарушением атрибута категории, что может улучшить его способность к обобщению.
5. Эксперимент, результат и обсуждение
В этом разделе мы применили модель идентификации, которая была реализована в классификаторах случайного леса и MLP, а также метод извлечения признаков в предыдущем материале.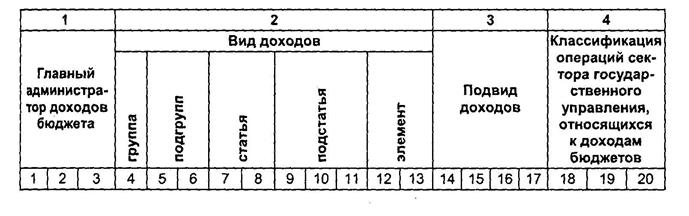 Условия эксперимента показаны в таблице 1.
Условия эксперимента показаны в таблице 1.
| ||||||||||
Изображение Calasetech в этой работе было применено Калифорнийский технологический институт как источник данных, содержащий 30607 изображений [16]. Данные изображения собираются из изображений Google, из которых были отсеяны неподходящие образцы. После сбора мы реализовали этап шифрования.
Перед шифрованием мы разделили набор данных на 1000 файлов размером 512 КБ, а затем зашифровали части с помощью восьми алгоритмов шифрования (как показано в таблице 2) в режимах ECB и CBC, что было выполнено программным обеспечением OPENSSL. Был применен один и тот же случайный ключ, когда этап обучения и этап тестирования находятся как в режиме ECB, так и в режиме CBC. IV, используемый в режиме CBC, произвольно создается OPENSSL.
IV, используемый в режиме CBC, произвольно создается OPENSSL.
| |||||||||||||||||||
5.1. Индекс оценки
Мы применяем четыре индекса для измерения модели классификации. TP (истинно положительный) представляет собой количество правильных примеров, которые приговариваются к правильным; TN (истинно отрицательный) представляет собой количество правильных примеров, которые приговариваются к неправильным; FP (ложноположительный) представляет собой количество ошибочных примеров, которые приговариваются к правильным; FN (ложноотрицательный) представляет количество неправильных примеров, которые приговариваются к неправильным, как показано в Таблице 3 [17].
| ||||||||||||||
Определение 3. (точность). Под точностью понимается соотношение приговоров в выборках к правильным:
Определение 4. (отзыв). Отзыв индекса относится к пропорции правильных выборок:
Определение 5. ( F 1-балл). Среднее гармоническое значение точности и отзыва выглядит следующим образом:
Определение 6. (точность). Точность определяется как доля образцов, которые правильно классифицированы во всем наборе данных: мы применили десятикратную стратегию перекрестной проверки для расчета точности идентификации в нашем эксперименте.Наконец, мы получили распределение точности идентификации и средние значения точности, отзыва и F 1-балла.
5.2. Результат и анализ
5.2.1. Оценка в режиме ECB
Для проведения эксперимента мы разделили базу данных на две части: 30% сбор как тестовый набор, а другой как обучающий набор. Наблюдая за оценкой классификатора (рисунки 4–6), результат эксперимента можно сделать успешным.
На рисунке 5 показано, что в классификаторе случайного леса точность идентификации в восьми алгоритмах шифрования составляет от 50% до 85%.Показатели точности идентификации DES и IDEA выше 80%. Показатели точности Camellia, 3DES и SMS4 составляют от 69% до 77%, в то время как показатели точности AES-256 и Blowfish составляют 58%, что явно ниже, чем у других.
На рисунке 5 показано, что в классификаторе RS степень точности идентификации в восьми алгоритмах шифрования составляет от 78% до 100%. Показатели точности идентификации AES-128, Camellia-128, DES, 3DES и IDEA составляют 100%. Для криптосистем Blowfish и SMS4 точность также достигла 95% и 98%. А для AES-256 точность составляет 78%.
А для AES-256 точность составляет 78%.
Уровень точности — это индекс, который отражает истинно правильную пропорцию правильно спрогнозированных данных. Мы можем сделать вывод, что наша схема извлечения признаков помогает классификатору MLP почти правильно предсказывать истину. Средняя точность MLP лучше, чем в случайном лесу.
На рисунке 6 показано, что для случайного леса классификатора коэффициент отзыва восьми криптосистем в режиме ECB составляет от 65% до 72% и распределяется равномерно.Средняя скорость отзыва AES-128 и AES-256 составляет более 70%. Уровень отзыва остальной криптосистемы колеблется от 65% до 68%.
На рисунке 6 коэффициент отзыва классификатора MLP колеблется от 21% до 78%. Скорость отзыва алгоритма SMS4 самая лучшая, она достигает 78%. Частота отзыва AES-256 и Blowfish составляет 44% и 40%. Уровень отзыва AES-128, Camellia, 3DES и IDEA составляет от 31% до 24%. Криптосистема DES имеет худший показатель отзыва — 21%.
Коэффициент отзыва — это доля правильной классификации в правом примере.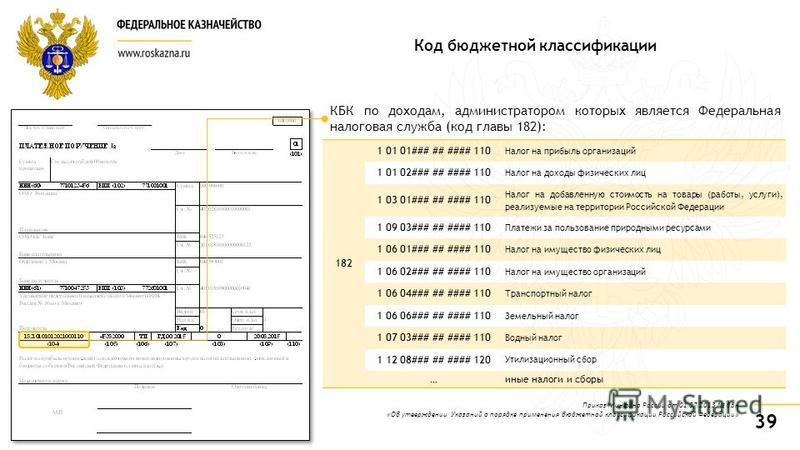 Мы можем сделать вывод, что наш метод извлечения признаков в классификаторе MLP будет пропускать некоторые правильные образцы, в то время как он имеет лучшую производительность, чтобы найти больше правильных образцов. А для криптосистемы классификатор SMS4 MLP демонстрирует сильную дифференциацию.
Мы можем сделать вывод, что наш метод извлечения признаков в классификаторе MLP будет пропускать некоторые правильные образцы, в то время как он имеет лучшую производительность, чтобы найти больше правильных образцов. А для криптосистемы классификатор SMS4 MLP демонстрирует сильную дифференциацию.
Индекс F 1-балл всесторонне измеряет точность и отзывчивость, которые отражают способность классифицировать правильный образец. На рис. 7 показано, что для случайного леса показатель F 1 составляет от 63% до 74%. Показатели F 1 для Camellia, DES, 3DES и IDEA превышают 68%.А у F 1-балльная оценка AES-128, AES-256, Blowfish, 3DES и SMS4 варьируется от 63% до 68%, в то время как для классификатора MLP 1-балльная шкала F находится между 34%. и 56%.
5.2.2. Оценка в режиме CBC
По сравнению с режимом ECB, режим CBC более сложен и имеет более высокий уровень безопасности. Поэтому классификатору труднее идентифицировать криптосистему с зашифрованными текстами, зашифрованными в режиме CBC.
На рисунке 8 показано, что в режиме CBC степень точности классификатора случайного леса в восьми алгоритмах шифрования составляет от 11% до 17%.В целом точность идентификации DES и IDEA превышает 80%. Показатели точности Camellia, 3DES и SMS4 составляют от 69% до 77%, а показатели точности AES-256 и Blowfish — 58%, что явно ниже, чем у других.
На рисунке 9 показано, что в классификаторе RS частота отзыва идентификации в восьми алгоритмах шифрования составляет от 10% до 22%. А в классификаторе MLP степень отзыва идентификации в восьми алгоритмах шифрования составляет от 11% до 23%.
Из рисунка 10 мы можем сделать вывод, что для возможности поиска правильных выборок нет очевидной разницы между классификатором MLP и классификатором RS для режима CBC. В классификаторе RS для идентификации F 1 балл в восьми алгоритмах шифрования составляет от 10% до 19%. В классификаторе MLP для идентификации F 1 балл в восьми алгоритмах шифрования составляет от 12% до 24%.
Объединив данные, мы получили среднюю точность в двух режимах работы на Рисунке 10.На рисунке 11 точность классификации классификатора случайных лесов в режиме ECB стабильна и составляет более 83,0%, а среднее значение близко к 85,5%. Точность классификации режима CBC ниже, чем у режима ECB; средняя точность составляет 18,0%, но все же она выше, чем у случайной классификации на 12,5%.
Для классификатора MLP мы получили среднюю точность в двух режимах работы, показанных на рисунке 12. На рисунке 12 точность классификации классификатора случайных лесов в режиме ECB стабильна и составляет более 50.0%, а среднее значение близко к 53,0%. Точность классификации режима CBC ниже, чем у режима ECB; средняя точность 13,0%, близка к случайной классификации на 12,5%.
В то время как MLP имеет лучшую производительность по показателю точности и F 1 балл, классификатор случайных лесов имеет лучшую производительность по точности идентификации. Мы можем сделать вывод, что образец, который MLP предсказывает правильным, всегда правильный, в то время как он мог бы превратить некоторые правильные образцы в неправильные.Более того, точность индексов, отзыв, F 1 балл и точность в режиме CBC в среднем будут ниже, чем в режиме ECB.
Мы можем сделать вывод, что образец, который MLP предсказывает правильным, всегда правильный, в то время как он мог бы превратить некоторые правильные образцы в неправильные.Более того, точность индексов, отзыв, F 1 балл и точность в режиме CBC в среднем будут ниже, чем в режиме ECB.
Если средний уровень точности идентификации превышает 12,5%, мы относим прогресс идентификации на основе нашей функции.
5.3. Сравнение с существующими схемами
В таблице 4 показано сравнение результатов предыдущих работ. Из таблицы видно, что наша схема идентификации криптосистемы имеет более высокую точность идентификации и может поддерживать больше видов задач идентификации криптосистем.Точность идентификации в режиме ECB составляет 84,5% при использовании классификатора случайного леса, что выше, чем у других существующих работ.
| ||||||||||||||||||||||||||||||||||||||||
 5%
5%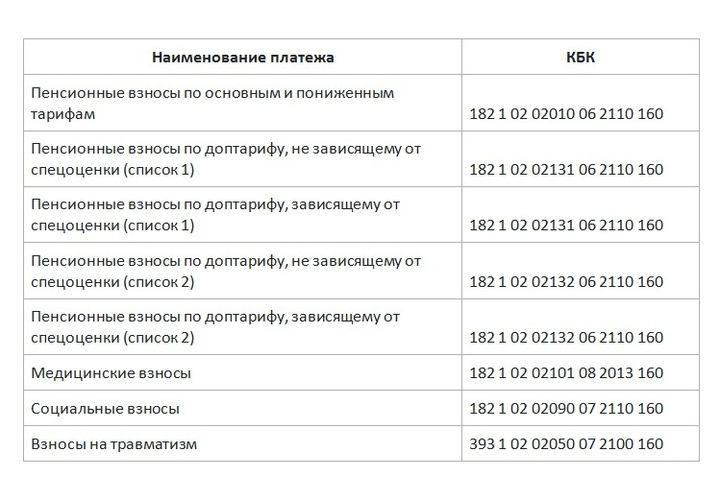 Во-вторых, мы также можем отобразить потоковый шифр и шифр с открытым ключом в криптосистему для распознавания, чтобы улучшить применимость, надежность и универсальность схемы. Наконец, мы оптимизируем разные классификаторы машинного обучения для разных криптосистем, чтобы повысить точность идентификации.
Во-вторых, мы также можем отобразить потоковый шифр и шифр с открытым ключом в криптосистему для распознавания, чтобы улучшить применимость, надежность и универсальность схемы. Наконец, мы оптимизируем разные классификаторы машинного обучения для разных криптосистем, чтобы повысить точность идентификации. И поскольку идентификация прошла успешно, мы можем узнать, что статистическая ценность кода ASCII из зашифрованных текстов отражает некоторую информацию о шифровании. Это проблема для правила криптографии, что злоумышленник не может получить какую-либо информацию из зашифрованных текстов.
И поскольку идентификация прошла успешно, мы можем узнать, что статистическая ценность кода ASCII из зашифрованных текстов отражает некоторую информацию о шифровании. Это проблема для правила криптографии, что злоумышленник не может получить какую-либо информацию из зашифрованных текстов. (2016YFE0100600), Национальным фондом естественных наук Китая в рамках гранта 61872381, Проект открытого фонда государственной ключевой лаборатории технологий информационного обеспечения (KJ-15-008 ) и Государственная ключевая лаборатория криптографии и науки.
(2016YFE0100600), Национальным фондом естественных наук Китая в рамках гранта 61872381, Проект открытого фонда государственной ключевой лаборатории технологий информационного обеспечения (KJ-15-008 ) и Государственная ключевая лаборатория криптографии и науки. Основанный на правилах
подходов оказалось достаточным в случаях анализа эритроцитов и тромбоцитов и их
более подробно конфигурация исследуется на этапе сегментации.
Дифференцировка лейкоцитов — это подзадача общего анализа крови, требующая более сложных
классификационный подход.Сравнение результатов на основе правил, классических
представлены методы глубокого обучения. Машины опорных векторов и k-ближайший
Соседи были выбраны как представители классических подходов. Глубокое обучение
схема имеет преимущество в нахождении быстрых решений сложных проблем, связанных с
многомерная и иерархическая структура лежащих в основе решений. Это также облегчает
объем работы, необходимой специалистам-людям для разработки соответствующих дескрипторов.
Обсуждаемые здесь результаты включают многообещающие перечисление и описание функций.
интересующих объектов.Их линейная зависимость с золотым стандартом клинических результатов
доказали свою пригодность для анализа крови в пунктах оказания медицинской помощи.
Основанный на правилах
подходов оказалось достаточным в случаях анализа эритроцитов и тромбоцитов и их
более подробно конфигурация исследуется на этапе сегментации.
Дифференцировка лейкоцитов — это подзадача общего анализа крови, требующая более сложных
классификационный подход.Сравнение результатов на основе правил, классических
представлены методы глубокого обучения. Машины опорных векторов и k-ближайший
Соседи были выбраны как представители классических подходов. Глубокое обучение
схема имеет преимущество в нахождении быстрых решений сложных проблем, связанных с
многомерная и иерархическая структура лежащих в основе решений. Это также облегчает
объем работы, необходимой специалистам-людям для разработки соответствующих дескрипторов.
Обсуждаемые здесь результаты включают многообещающие перечисление и описание функций.
интересующих объектов.Их линейная зависимость с золотым стандартом клинических результатов
доказали свою пригодность для анализа крови в пунктах оказания медицинской помощи. Результаты классификации показали
превосходство сверточных нейронных сетей в нескольких важных аспектах. Способствовать
анализ изучил изученные параметры и проанализировал ошибочно классифицированные случаи по порядку
лучше понять, какие цитологические объекты являются наиболее хрупкими в частности
классификатор и почему.
Результаты классификации показали
превосходство сверточных нейронных сетей в нескольких важных аспектах. Способствовать
анализ изучил изученные параметры и проанализировал ошибочно классифицированные случаи по порядку
лучше понять, какие цитологические объекты являются наиболее хрупкими в частности
классификатор и почему. 5 0 0 75 173,75 681 см
/ Im0 Do
Q
BT
/ T1_0 1 Тс
10 0 0 10 310,4697 597,99985 тм
() Tj
0 0 1 рг
-8.95099 0 Тд
(10.1261 / rna.617107) Tj
0 г
-16.89598 0 Тд
(Доступ к самой последней версии на сайте doi 🙂 Tj
2.11101 1 тд
(2007 13: 1469-1472, первоначально опубликовано в Интернете 24 июля 2007 г.) Tj
/ T1_1 1 Тс
-2,11101 0 тд
(РНК) Tj
/ T1_0 1 Тс
0 1.00001 TD
(\ 240) Tj
0 1 ТД
(Тобиас М \ 374ller, Николь Филиппи, Томас Дандекар и др.) Tj
Т *
(\ 240) Tj
/ T1_2 1 Тс
15 0 0 15 52 648 тм
(Отличительные виды) Tj
ET
52 586 кв.м.
557 586 л
0 0 мес.
S
BT
ET
BT
/ T1_0 1 Тс
11 0 0 11 142.94202 559,99997 тм
(\ 240) Tj
/ T1_2 1 Тс
-5.11299 1 Td
(Ссылки) Tj
ET
BT
/ T1_0 1 Тс
10 0 0 10 163 551,99994 тм
(\ 240) Tj
29.72884 1 тд
() Tj
0 0 1 рг
/ T1_2 1 Тс
-29.72884 0 Тд
(http://rnajournal.cshlp.org/content/13/9/1469.full.html#ref-list-1)Tj
0 г
/ T1_0 1 Тс
0 1.00001 TD
(Эта статья цитирует 9 статей, 2 из которых доступны бесплатно по адресу:) Tj
ET
BT
/ T1_0 1 Тс
11 0 0 11 144.94208 525.99997 тм
(\ 240) Tj
/ T1_2 1 Тс
-3,44598 1 тд
(Лицензия) Tj
ET
BT
/ T1_2 1 Тс
11 0 0 11 112,86 188 495,99997 тм
(Сервис) Tj
-3.
5 0 0 75 173,75 681 см
/ Im0 Do
Q
BT
/ T1_0 1 Тс
10 0 0 10 310,4697 597,99985 тм
() Tj
0 0 1 рг
-8.95099 0 Тд
(10.1261 / rna.617107) Tj
0 г
-16.89598 0 Тд
(Доступ к самой последней версии на сайте doi 🙂 Tj
2.11101 1 тд
(2007 13: 1469-1472, первоначально опубликовано в Интернете 24 июля 2007 г.) Tj
/ T1_1 1 Тс
-2,11101 0 тд
(РНК) Tj
/ T1_0 1 Тс
0 1.00001 TD
(\ 240) Tj
0 1 ТД
(Тобиас М \ 374ller, Николь Филиппи, Томас Дандекар и др.) Tj
Т *
(\ 240) Tj
/ T1_2 1 Тс
15 0 0 15 52 648 тм
(Отличительные виды) Tj
ET
52 586 кв.м.
557 586 л
0 0 мес.
S
BT
ET
BT
/ T1_0 1 Тс
11 0 0 11 142.94202 559,99997 тм
(\ 240) Tj
/ T1_2 1 Тс
-5.11299 1 Td
(Ссылки) Tj
ET
BT
/ T1_0 1 Тс
10 0 0 10 163 551,99994 тм
(\ 240) Tj
29.72884 1 тд
() Tj
0 0 1 рг
/ T1_2 1 Тс
-29.72884 0 Тд
(http://rnajournal.cshlp.org/content/13/9/1469.full.html#ref-list-1)Tj
0 г
/ T1_0 1 Тс
0 1.00001 TD
(Эта статья цитирует 9 статей, 2 из которых доступны бесплатно по адресу:) Tj
ET
BT
/ T1_0 1 Тс
11 0 0 11 144.94208 525.99997 тм
(\ 240) Tj
/ T1_2 1 Тс
-3,44598 1 тд
(Лицензия) Tj
ET
BT
/ T1_2 1 Тс
11 0 0 11 112,86 188 495,99997 тм
(Сервис) Tj
-3. 16599 1 тд
(Оповещение по электронной почте) Tj
ET
BT
/ T1_0 1 Тс
10 0 0 10 167 487,99994 тм
(\ 240) Tj
19.06496 1 тд
() Tj
0 0 1 рг
/ T1_2 1 Тс
-4,892 0 Тд
(нажмите здесь.) Tj
0 г
/ T1_0 1 Тс
-14.17296 0 Тд
(верхний правый угол статьи или) Tj
Т *
(Получайте бесплатные уведомления по электронной почте, когда новые статьи цитируют эту статью — зарегистрируйтесь \
в коробке на) Tj
ET
52 470 кв.м.
557 470 л
0 0 мес.
S
BT
ET
q
468 0 0 60 70,5 159 см
-1.00001 TL / Im1 Do
Q
52 119 кв.м.
557119 л
0 0 мес.
S
BT
ET
BT
/ T1_2 1 Тс
10 0 0 10 244,8089 83,99997 тм
() Tj
0 0 1 рг
-19.28089 0 Тд
(http://rnajournal.cshlp.org/subscriptions)Tj
0 г
/ T1_0 1 Тс
9 0 0 9 135.02492 94 тм
(перейти к:) Tj
/ T1_1 1 Тс
-2,11101 0 тд
(РНК) Tj
/ T1_0 1 Тс
-7.11398 0 Td
(Чтобы подписаться на) Tj
ET
52 68 кв.м.
557 68 л
0 0 мес.
S
BT
ET
BT
/ T1_0 1 Тс
10 0 0 10 54 42 тм
(Copyright \ 251 2007 RNA Society) Tj
ET
BT
/ T1_0 1 Тс
8 0 0 8 497,85565 779 тм
() Tj
0 0 1 рг
-16.44997 0 Тд
(Пресса лаборатории Колд-Спринг-Харбор) Tj
0 г
-14.
16599 1 тд
(Оповещение по электронной почте) Tj
ET
BT
/ T1_0 1 Тс
10 0 0 10 167 487,99994 тм
(\ 240) Tj
19.06496 1 тд
() Tj
0 0 1 рг
/ T1_2 1 Тс
-4,892 0 Тд
(нажмите здесь.) Tj
0 г
/ T1_0 1 Тс
-14.17296 0 Тд
(верхний правый угол статьи или) Tj
Т *
(Получайте бесплатные уведомления по электронной почте, когда новые статьи цитируют эту статью — зарегистрируйтесь \
в коробке на) Tj
ET
52 470 кв.м.
557 470 л
0 0 мес.
S
BT
ET
q
468 0 0 60 70,5 159 см
-1.00001 TL / Im1 Do
Q
52 119 кв.м.
557119 л
0 0 мес.
S
BT
ET
BT
/ T1_2 1 Тс
10 0 0 10 244,8089 83,99997 тм
() Tj
0 0 1 рг
-19.28089 0 Тд
(http://rnajournal.cshlp.org/subscriptions)Tj
0 г
/ T1_0 1 Тс
9 0 0 9 135.02492 94 тм
(перейти к:) Tj
/ T1_1 1 Тс
-2,11101 0 тд
(РНК) Tj
/ T1_0 1 Тс
-7.11398 0 Td
(Чтобы подписаться на) Tj
ET
52 68 кв.м.
557 68 л
0 0 мес.
S
BT
ET
BT
/ T1_0 1 Тс
10 0 0 10 54 42 тм
(Copyright \ 251 2007 RNA Society) Tj
ET
BT
/ T1_0 1 Тс
8 0 0 8 497,85565 779 тм
() Tj
0 0 1 рг
-16.44997 0 Тд
(Пресса лаборатории Колд-Спринг-Харбор) Tj
0 г
-14. 61898 0 Td
(19 мая 2021 г. — опубликовано) Tj
0 0 1 рг
-8.78098 0 Тд
(rnajournal.cshlp.org) Tj
0 г
-8.11398 0 тд
(Загружено с) Tj
ET конечный поток
эндобдж
104 0 объект
> / Filter / FlateDecode / Height 300 / Length 65192 / Name / X / Subtype / Image / Type / XObject / Width 1046 >> stream
HklSs | / qbI $ q! XHNkICJAXhrZ7Lc] մ vM &
QJ [J-vlEd >> ‘>} Y’Fz? I | E
61898 0 Td
(19 мая 2021 г. — опубликовано) Tj
0 0 1 рг
-8.78098 0 Тд
(rnajournal.cshlp.org) Tj
0 г
-8.11398 0 тд
(Загружено с) Tj
ET конечный поток
эндобдж
104 0 объект
> / Filter / FlateDecode / Height 300 / Length 65192 / Name / X / Subtype / Image / Type / XObject / Width 1046 >> stream
HklSs | / qbI $ q! XHNkICJAXhrZ7Lc] մ vM &
QJ [J-vlEd >> ‘>} Y’Fz? I | E
 Большинство поисковых систем и каталогов имеют простой способ сообщить о неработающих ссылках.
Большинство поисковых систем и каталогов имеют простой способ сообщить о неработающих ссылках.